See the latest book content here.
9 Deep Reinforcement Learning
In this chapter, we focus on deep reinforcement learning, which is a combination reinforcement learning and deep learning. This combination has enabled machines for solving complex decision problems in robotics, healthcare, finance, automatic vehicle control, to name a few.
Learning outcomes from this chapter:
Markov decision processes
Reinforcement learning
Deep reinforcement learning
9.1 Introduction
Sequential decision making is a key topic in machine learning. In this framework, an agent continuously interacts with and learn from an uncertain environment. A sequence of actions taken by the agent decides how the agent interacts with the environment and learn from it. Sequential decision making finds crucial applications in many domains, including healthcare, robotics, finance, and self-driving cars.
In certain cases decision making processes can be detached from precise details of information retrieval and interaction, and however, in many other practical cases the two are coupled. In the latter case, the agent observes the system, gains information and make decisions simultaneously. This is where techniques such as Markov Decision Processes (MDP), Partially Observable Markov Decision Processes (POMDP), and Reinforcement Learning (RL) play significant roles.
Over the last few years, RL has become increasingly popular in addressing important sequential decision making problems. This success is mostly due to the combination of RL with deep learning techniques thanks to the ability of deep learning to successfully learn different levels of abstractions from data with a lower prior knowledge. Deep RL has created an opportunity for us to train computers to mimic some human solving capabilities.
RL is an interdisciplinary field, addressing problems in
- Optimal control (Engineering)
- Dynamic programming (Operational Research)
- Reward systems (Neuro-science)
- Operant conditioning (Psychology)
In all these different areas of science, there is a common goal to solve the problem of how to make optimal sequential decisions. RL algorithms are motivated from the human decision making based on “rewards provide a positive reinforcement for an action”. This behavior is studied in Neuro-science as reward systems and in Psychology as conditioning.
9.1.1 Applications
Let’s look at some examples where RL plays an important role.
Robitics: Imagine a robot trying to move from point A to point B, starting with a lack of knowledge on its surroundings. In this process, it tries different leg and body moves. From each successful or failed move, it learns and uses this experience in making the next moves.
Vehicle control: Think of you trying to fly a drone. In the beginning you have little or no information on what controls to apply to make a successful flight. As you start applying the controls, you get feedback based on how the drone moving in the air. You use this feedback to decide the next controls.
-
Learning to play games: This is another major area where RL has been very successful recently. You must have heard about Google Deepmind’s Alpha Go defeating world’s best Go player Lee Sedol, or Gerald Tesaro’s software agent defeating world Backgammon Champion. These agents use RL.

Atari Breakout played by Google Deepmind’s Deep Q-learning. To see a video recording of the game, click here. Medical treatment planning: RL finds application in planning medical treatment for a patient. The goal is to learn a sequence of treatments based the patient’s reaction to the past treatments and the patient’s current state. The results of the treatments are obtained only at the end, and hence the decisions need to be taken very carefully as it can be a life and death situation.
Chatbots: Think of Microsoft’s chatbots Tay and Zo, and personal assistants like Siri, Google Now, Cortana, and Alexa. All the agents use RL in improving their conversation with a human user.
9.1.2 Key characteristics
There are some key characteristics that separate RL from the other optimization paradigms and supervised learning methods in machine learning. Some of them are listed below.
No “supervision”: There is no supervisor, no labels telling the agent what is the best action to take. For example, in the robotics example, there is no supervisor guiding the robot in choosing the next moves.
Delayed feedback: Even though there is a feedback after every action, most often the feedback is delayed. That is, the effect of the actions taken by the agent might not be observed immediately. For example, when flying a drone from one point to another, moving it aggressively may seem to be nice as the drone moving towards the target quickly, however, the agent might realize later that this aggressive move made the drone to crash into something.
Sequential decisions: The notion of time is essential in RL: each action effects the next state of the system and that further influences the agent’s next action.
Effects of actions on observations: Another key characteristic of RL is that the feedback the agent obtains is in fact a function of the actions taken by the agent and the uncertainty in the environment. In contrary, for the supervised learning paradigm of machine learning, samples in the training data are assumed to be independent of each other.
9.2 Preliminaries
In this section, we establish some preliminaries that are necessary for understanding the methods discussed later.
9.2.1 Markov chain
Let \(Z_0, Z_1, Z_2, \dots\) be a sequence of random objects. We say that the sequence is Markov if for every \(t \in \{1, 2, \dots\}\),
\[ \mathbb{P}\left(Z_t \in \cdot | Z_0 = z_0, Z_1 = z_1, \dots, Z_{t-1} = z_{t-1}\right) = \mathbb{P}\left(Z_t \in \cdot| Z_{t-1} = z_{t-1}\right), \] for any sequence \(z_0, z_1, \dots, z_{t-1}\). In other worlds, if \(t\) indicates time steps, given the current state of a Markov chain, its future is independent of its past.
9.2.2 Contraction mapping
Let \(F\) be a a mapping on a complete metric space \((\mathscr M, \mathcal D)\) into itself. Any \(M \in \mathscr M\) such that \(F(M) = M\) is called a fixed point of the mapping \(F\). Further, \(F\) is said to be contraction if there exists a constant \(\gamma < 1\) such that
\[ \mathcal{D}\left(F(M), F(M')\right) \leq \gamma \mathcal{D}\left(M, M'\right), \] for every \(M, M' \in \mathscr M\).
Fixed point theorem is also known as the method of successive approximations or the principle of contraction mappings
Theorem 9.1 (Fixed point theorem): Every contraction mapping defined on a complete metric space has a unique fixed point.
Finding the fixed point is easy: start at an arbitrary point \(M_0 \in \mathscr M\) and recursively apply
\[ M_k = F(M_{k-1}). \] for each \(k = 1, 2,3, \dots\). Then the sequence \(M_0, M_1, M_2, \dots\) converges to the unique fixed point.
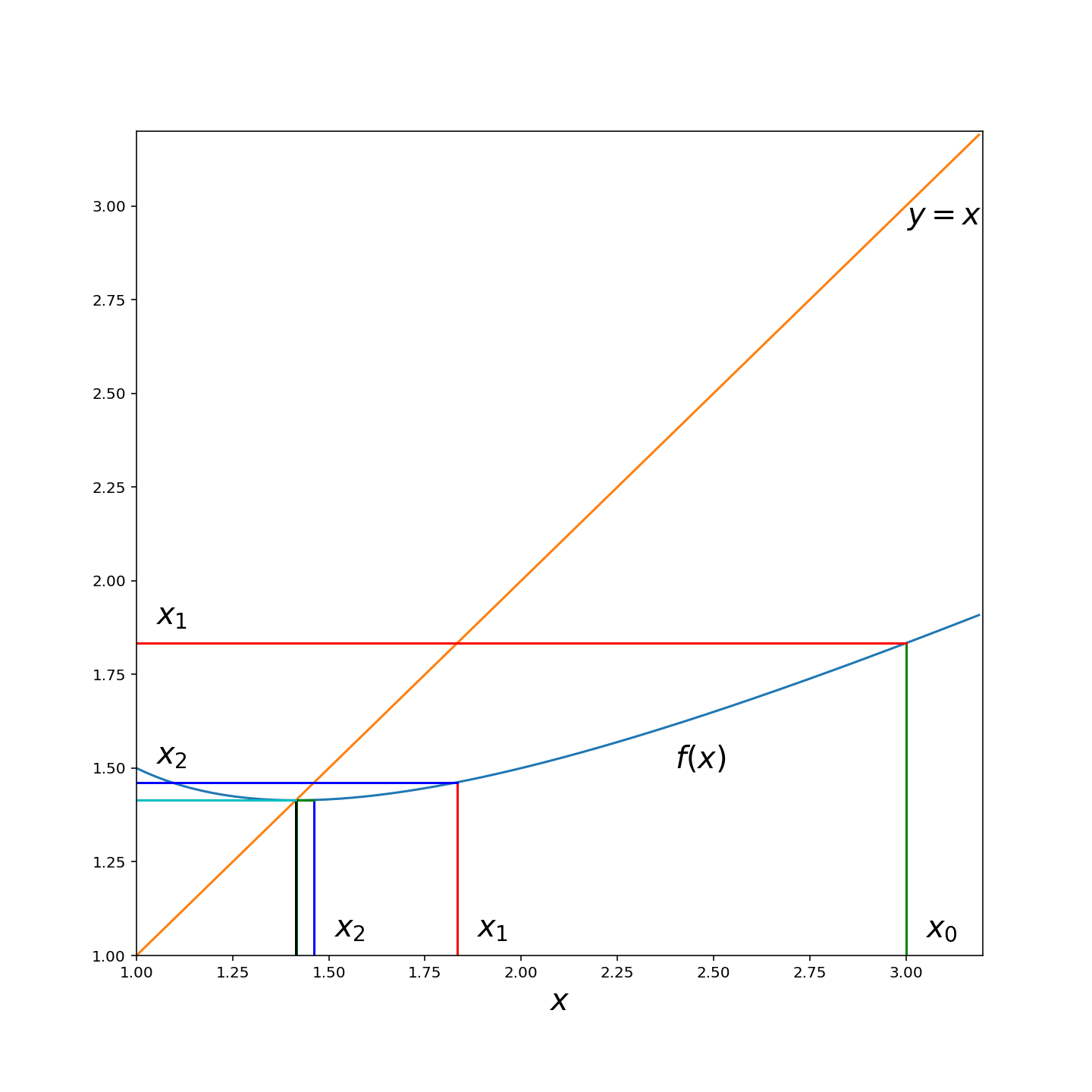
For example consider the following real-valued function \(f(x)\) on \(\mathscr M = [1, 3.5]\) with \(\mathcal D\) being the Euclidean distance. \[ f(x) = \frac{1}{2}\left(x + \frac{2}{x}\right). \] It is easy to show that \(f(x)\) is a contraction mapping with a fixed point at \(\sqrt{2}\). The following figure illustrates the convergence of the sequence \(x_0 = 3, x_1 = f(x_0), x_2 = f(x_1), \dots\) to \(\sqrt{2}\).
9.3 Markov Decision Processes
To understand RL, we first need to understand the framework of Markov Decision Processes. They are the underlying stochastic models in RL for making decisions. Essentially, RL is the problem we address when this underlying model is either too difficult to solve or unknown in order to find the optimal strategy in advance.
9.3.1 An Example
As a first example, consider a scenario focusing on the engagement level of a student. Assume that there are \(L\) levels of engagement, \(1,2,\ldots,L\), where at level \(1\) the student is not engaged at all and at the other extreme, at level \(L\), she is maximally engaged. Our goal is to maintain engagement as high as possible over time. We do this by choosing one of two actions at any time instant. (0): “do nothing” and let the student operate independently. (1): “stimulate” the student. In general, stimulating the student has a higher tendency to increase her engagement level, however this isn’t without cost as it requires resources.
We may denote the engagement level at (discrete) time \(t\) by \(X(t)\), and for simplicity we assume here that at any time, \(X(t)\) either increases or decreases by \(1\). An exception exists at the extremes of \(X(t) = 1\) and \(X(t) = L.\) In these extreme cases the student engagement either stays the same or increases/decreases respectively by \(1\). The actual transition of engagement level is random, however we assume that if our action is “stimulate” then there is more likely to be an increase of engagement than if we “do nothing”.
The control problem is the problem of deciding when to “do nothing” and when to “stimulate”. For this we formulate a reward function and assume that at any time \(t\) our reward is,
Here \(\kappa\) is some positive constant and \(A(t) = 0\) if the action at time \(t\) is to “do nothing”, while \(A(t) = 1\) if the action is to “stimulate”. Hence the constant \(\kappa\) captures our relative cost of stimulation effort in comparison to the benefit of a unit of student engagement. We see that \(R(t)\) depends both on our action and the state.
The reward is accumulated over time into an optimization objective via,
where \(\gamma \in (0,1)\) and is called the discount factor. Through the presence of \(\gamma\), future rewards are discounted with a factor of \(\gamma^t\), indicating that in general the present is more important than the future. There can also be other types of objectives, for example finite horizon or infinite horizon average reward, however we only focus on this infinite horizon expected discounted reward case.
A control policy is embodied by the sequence of actions \(\{A(t)\}_{t=0}^\infty\). If these actions are chosen independently of observations then it is an open loop control policy. However, for our purposes, things are more interesting in the closed loop or feedback control case in which at each time \(t\) we observe the state \(X(t)\), or some noisy version of it. This state feedback helps us decide on \(A(t)\).
We encode the effect of an action on the state via a family of Markovian transition probability matrices. For each action \(a\), we set a transition probability matrix \(P^{(a)}\). In our case, as there are two possible actions, we have two matrices such as for example,
Hence for example in state \(1\) (first row), if we choose action \(0\) then the transitions follow \([1/2~~1/2~~0~\ldots 0]\), whereas if we choose action \(1\) then the transitions follow \([1/4~~3/4~~0~\ldots 0 ]\). That is for a given state \(i\), choosing action \(a\) implies that the next state is distributed according to \([P_{i1}^{(a)}~~ P_{i2}^{(a)}~~ \cdots ]\) (where most of the entries of this probability vector are \(0\) in this example).
In the case of MDP and POMDP these matrices are assumed known, however in the case of RL these matrices are unknown. The difference between MDP and POMDP is that in MDP we know exactly in which state we are in, whereas in POMDPs our observations are noisy or partial and only hint at the current state. Hence in general we can treat MDP as the basic case and POMDP and RL can be viewed as two variants of MDP. In the case of POMDP the state isn’t fully observed, while in the case of RL the transition probabilities are not known.
We don’t focus on POMDPs further in this course, but rather we continue with MDP and RL. For this, we first need to understand more technical aspects of MDP.
9.3.2 Formal framework
Formally, an MDP is a discrete stochastic control process where the agent starts at time \(t = 0\) in the environment with an observation \(\omega_0 \in \Omega\) about the initial state \(s_0 \in S\) of the system, where \(\Omega\) is the space of observations and \(S\) is the state space. At each time step \(t \in \{1,2,3, \dots \}\), (i) the agent obtains a reward with mean \(r_t\), (ii) the state of the system transits from \(s_t\) to a new state \(s_{t+1}\), and (iii) the agent obtains an observation \(\omega_{t+1}\).
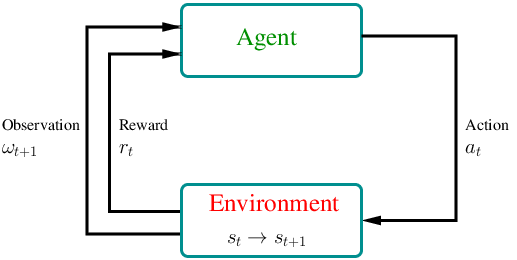
The key property of MDPs is that they satisfy the Markov property, which essentially states that the future is independent of the past given the current observation, and hence the agent has no interest in looking back at the full history.
Definition 9.1 : A descrete time stochastic control process is said to be Markov if for all \(t = 1, 2, \dots\),
\[\mathbb{P}\left(\omega_{t+1} |\omega_0, a_0, \dots, \omega_t, a_t\right) = \mathbb{P}\left(\omega_{t+1} |\omega_t, a_t\right)\] and \[\mathbb{P}\left(r_{t} |\omega_0, a_0, \dots, \omega_t, a_t\right) = \mathbb{P}\left(r_t |\omega_t, a_t\right)\]
Definition 9.2 : A descrete time stochastic control process is said to be fully observable if for all \(t = 1, 2, \dots\),
\[\omega_t = s_t.\]
Definition 9.3 : A Markov Decision Process is a fully observable descrete time stochastic control process which satisfies the Markov property.
An MDP is a 5-tuple \((S, A, T, R, \gamma)\), here
\(S\) is the state space of the system;
\(A\) is the action space;
\(T: S\times A \times S \to [0,1]\) is the transition function defining the conditional probabilities between the states;
\(R: S \times A \times S \to \mathbb R\) is the reward function such that for some constant \(R_{\max}\), \(R(s, a, s') \leq R_{\max}\) for all \(s, s' \in S\) and \(a \in A;\)
\(\gamma\) is the discount factor;
The agent selects an action at each time step according to a policy \(\pi \in \Pi\). Policies can be divided into stationary and non-stationary. A non-stationary policy depends on time, and they are useful for finite horizon case problems (i.e., there exists a \(K\) such that the agent takes actions only at \(t = 0, 1, \dots, K\)). In this chapter, we consider infinite horizons and stationary policies.
Stationary policies can be further divided into two classes:
Deterministic: There is a unique action \(a\) for each state \(s\) specified by a policy map \(\pi(s) : S \to A\).
Stochastic: The agent takes an action \(a\) at state \(s\) according to a probability distribution given by the policy function \(\pi(s, a): S\times A \to [0,1]\). Note that \(\int_{a \in A} \pi(s, a) \mathrm d a = 1\) for all \(s \in S\).
With these notions in mind, we can see that
the transition probability \[T(s_t, a_t, s_{t+1}) = \mathbb{P}\left(s_{t+1}| s_t, a_t\right),\] and
the average reward \[r_t = \mathbb{E}\left[ R(s_t, a, s_{t+1}) \right],\] where \(a_t \sim \pi(s_t, \cdot)\) and \(s_{t+1} \sim T(s_t, a_t, \cdot).\)
The following figure illustrates the transitions in an MDP.
![]()
9.3.3 Goal of the agent
As in Example 9.3.1, the goal of the agent is to maximize the expected total discounted reward defined by the value function \(V^{\pi}(s) : S \to \mathbb R\):
\[ V^{\pi}(s) := \mathbb{E}\left[ \sum_{t = 0}^\infty \gamma^{t} R(s_t, a_t, s_{t+1})| s_0 = s, \pi \right], \] where conditioning on \(\pi\) implies that at each step, action \(a_t\) is selected according to the policy \(\pi\).
Observe that under the stationary assumption, for all \(t\),
\[ V^{\pi}(s) = \mathbb{E}\left[ \sum_{k = 0}^\infty \gamma^{k} R(s_{t+k}, a_{t+k}, s_{t+k+1})| s_t = s, \pi \right]. \] Then, the optimal expected return (i.e., optimal value function) is given by
\[ V^*(s) = \max_{\pi \in \Pi} V^{\pi}(s). \]
The following result, Theorem 9.2, by (Puterman 1994) states that there exists a deterministic optimal policy that maximizes the value function. That is, the agent has no need to sample action from a probability distribution to achieve maximum expected discounted reward.
Theorem 9.2 (Puterman [1994]): For any infinite horizon discounted MDP, there always exists a deterministic stationary policy \(\pi\) that is optimal.
From Theorem 9.2, we can assume that the set of policies \(\Pi\) contains only deterministic stationary polices.
Further, observe that the action taken by the agent at time \(t\) determines not only the reward at time \(t\), but also the states after time \(t\) and therefore the rewards after \(t\). Hence, the agent has to choose the policy strategically in order to maximize the value function. Now onwards we focus on developing such optimization algorithms.
Exercise: Determine \(S\), \(A\), \(T\), and \(R\) for Example 9.3.1.
9.3.4 Bellman equations
The following theorem establishes the recursive behavior of the value function: Bellman equations for value functions.
Theorem 9.3 : For any policy \(\pi \in \Pi\),
\[ V^{\pi}(s) = \sum_{s' \in S} T(s, \pi(s), s') \left[ R(s, \pi(s), s') + \gamma V^{\pi}(s')\right]. \]
Proof. From the definition of the value function,
\[\begin{align*} V^{\pi}(s) &= \mathbb{E}\left[R(s, a_0, s_{1}) + \sum_{t = 0}^\infty \gamma^{t} R(s_t, a_t, s_{t+1})| s_0 = s, \pi \right]\\ &= \mathbb{E}_{s' \sim T(s, \pi(s), \cdot)} \left[R(s, a_0, s')\right] + \mathbb{E}_{s' \sim T(s, \pi(s), \cdot)} \left[ \sum_{t = 1}^\infty \gamma^{t} R(s_t, a_t, s_{t+1})| s_0 = s, a_0 = \pi(s)\right]\\ &= \sum_{s' \in S} T(s, \pi(s), s') R(s, \pi(s), s') + \gamma \sum_{s' \in S} T(s, \pi(s), s') \left[ \sum_{t = 1}^\infty \gamma^{t-1} R(s_t, a_t, s_{t+1})| s_1 = s', \pi\right]\\ &= \sum_{s' \in S} T(s, \pi(s), s') R(s, \pi(s), s') + \gamma \sum_{s' \in S} T(s, \pi(s), s') V^{\pi}(s'). \end{align*}\]
In particular, for an optimal policy \(\pi^*\), we have:
Theorem 9.4 : For all \(s \in S\),
where \(r(s,a) = \mathbb{E}_{s' \sim T(s, a, \cdot)}[R(s, a, s')]\) for every pair \((s,a)\).
Proof. Observe that, for each \(s \in S\),
\[\begin{align} V^*(s) &= \max_{\pi \in \Pi} V^{\pi}(s)\\ &= \max_{\pi \in \Pi} \mathbb{E}_{a \sim \pi(s), s' \sim T(s, a, \cdot)}\left[ R(s, a, s') + \gamma V^{\pi}(s')\right]\\ &\leq \max_{a \in A} \left[ r(s, a) + \gamma \sum_{s' \in S} T(s, a, s')\max_{\pi \in \Pi} V^{\pi}(s')\right]\\ &= \max_{a \in A} \left[ r(s, a) + \gamma \sum_{s' \in S} T(s, a, s') V^{*}(s')\right]. \end{align}\]
If the inequality is strict, we can improve the value of state \(s\) by using a policy (possibly non-stationary) that uses an action from \(\arg\max_{a \in A} r(s,a)\) in the first step.
In fact, (Puterman 1994) shows as a consequence of the fixed point theorem that \(V^*\) is a unique solution of (9.5).
In addition to value functions, there are few other functions interests us. Among them most important one is Q-value function \(Q^{\pi}(s,a): S \times A \to \mathbb R\) defined by
\[ Q^{\pi}(s, a) = \mathbb{E}\left[ \sum_{t = 0}^\infty \gamma^{t} R(s_t, a_t, s_{t+1})| s_0 = s, a_0 = a \right]. \] The Q-value is essentially the expected total discounted reward when started in state \(s\) with initial action \(a\), and following policy \(\pi\) at each step \(t = 1, 2, \dots.\)
Just like the value function, we can show that the Q-value function also satisfies Bellman equation as follows:
\[ Q^{\pi}(s, a) = \sum_{s' \in S} T(s, a, s') \left[ R(s, a, s') + \gamma Q^{\pi}(s', \pi(s'))\right]. \] Also, similar to value functions, for each \((s,a)\) pair, the optimal Q-value functions is defined by \[ Q^*(s, a) = \max_{\pi \in \Pi} Q^{\pi}(s,a). \] The main advantage of Q-value function is that the optimal policy can be computed directly from the Q-value function using,
\[ \pi^*(s) = \arg\max_{a \in A} Q^*(s,a), \] where use some deterministic method to select a solution if \(\arg\max_{a \in A} Q^*(s,a)\) is a set.
9.3.5 Iterative algorithms
From the definitions of \(V^{\pi}(s)\) and \(Q^{\pi}(s,a)\), it is immediately obvious that an easy way to estimate them is by using Monte Carlo algorithms, i.e., for each state \(s\) or each state-action pair \((s,a)\), run several simulations starting from \(s\) or \((s,a)\) and take sample mean of the values or the Q-values obtained. This is not possible in practice when limited data is available. Even when large data is available, Monte Carlo algorithms may not be computationally efficient compared to the algorithms discussed below.
Assume that both the state space \(S\) and the action space \(A\) are finite and discrete. Further assume that the discount factor \(\gamma < 1\).
9.3.5.1 Value iteration
It is an indirect method that finds an optimal function \(V^*\), but not optimal policy. In this implementation, we assume that it is easy to compute \(r(s,a) = \mathbb{E}_{s' \sim T(s, a, \cdot)}[R(s, a, s')]\) for any pair \((s,a)\).
| Algorithm : Pseudocode for value iteration |
- Start with some arbitrary initial values \(\mathbf{v}_0 = \{v_0(s) : s \in S \}\) and fix a small \(\epsilon > 0\)
repeat for \(t = 1, 2, \dots\) until \(\|\mathbf{v}_k - \mathbf{v}_{k-1}\|_{\infty} \leq \epsilon\)
- For every \(s \in S\), \[v_k(s) = \max_{a \in A} \left[r(s,a) + \gamma \sum_{s' \in S} T(s, a, s') v_{k-1}(s')\right]\]
- Determine optimal policy by \[\pi(s) = \arg\max_{a \in A} \left[r(s,a) + \gamma \sum_{s' \in S} T(s, a, s') v_{k-1}(s')\right]\]
The following theorem establishes that value iteration algorithm convergences to the optimal value. This is again a consequence of the fixed point theorem for contraction mappings.
Theorem 9.5 (Puterman [1994]):
The above algorithm converges linearly at rate \(\gamma\):
\[ \|\mathbf{v}_k - \mathbf V^*\|_{\infty} \leq \frac{\gamma^k}{1 - \gamma} \|\mathbf{v}_1 - \mathbf{v}_0\|_{\infty}, \]
where \(\mathbf V^* = \{V^*(s) : s \in S\}\).9.3.5.2 Q-value iteration
Observe that \[ V^*(s) = \max_{a \in A} Q^*(s,a), \quad \forall s \in S. \] Therefore, the Bellman equations for the Q-value function can be rewritten as follows: \[ Q^*(s,a) = r(s,a) + \gamma \sum_{s' \in S} T(s, a, s') \left(\max_{a' \in A} Q^*(s', a')\right). \] The Q-value iteration algorithm below takes advantage of this relation:
| Algorithm : Pseudocode for Q-value iteration |
- Start with some initial Q-values \(\mathbf{Q}_0 = \{Q_0(s, a) : s \in S, a \in A\}\) and fix a small \(\epsilon > 0\)
repeat for \(t = 1, 2, \dots\) until \(\|\mathbf{Q}_k - \mathbf{Q}_{k-1}\|_{\infty} \leq \epsilon\)
- For every \(s \in S\) and \(a \in A\), \[Q_k(s, a) = r(s,a) + \gamma \mathbb{E}_{s'} \left[ \max_{a' \in A} Q_{k-1}(s', a') \Big| s, a\right]\]
Similar to the value iteration, since Q-values also satisfy contraction mapping, using the fixed value theorem, we can show that \(\mathbf{Q}_k\) converges to the unique optimal Q-value function \(\mathbf{Q}^*\) linearly.
9.3.5.3 Policy iteration
This is a direct method that finds the optimal policy.
| Algorithm : Pseudocode for policy iteration |
- Start with some initial policy \(\boldsymbol{\pi}_0 = \{\pi_0(s) : s \in S\}\) and initial value vector \(\mathbf{v}_0\)
repeat for \(t = 1, 2, \dots\) until \(\boldsymbol{\pi}_k = \boldsymbol{\pi}_{k-1}\)
For every \(s \in S\), \[\pi_k(s) = \arg\max_{a \in A} \left(r(s,a) + \gamma \mathbb{E}_{s'} \left[ v_{k-1}(s') \Big| s, a\right]\right)\] for all \(s \in S\)
Set \(\mathbf{v}_k\) as the value of \(\boldsymbol{\pi}_k\) (compute these values using steps in the value iteration algorithm)
9.3.5.4 Issues with the above three iteration methods
For most practical problems, the state space is higher-dimensional (probably continuous), and the transition probabilities and reward function of the underlying MDP model are either unknown or extremely difficult to compute. For instance, consider the engagement level example, Example 9.3.1. The transition matrices (9.3) and (9.4) are a postulated model of reality. In some situations the parameters of such matrices may be estimated from previous experience, however often this isn’t feasible due to changing conditions or lack of data. So the above iteration algorithms are hard to implement. RL algorithms are useful for solving such problems. We now focus on RL algorithms.
9.4 Reinforcement Learning via Q-Learning
In this section, we explore one class of RL algorithms called Q-learning. The main idea of this method is to learn the Q-function without explicitly decomposing \(Q(s,a)\) into \(T\), \(V\) and \(R\). Observe from the Bellman equation of Q-value function that if we were to know \(Q(s,a)\) for every state \(s\) and action \(a\), then we can also compute the optimal policy by selecting the \(a\) that maximizes \(Q(s,a)\) for every \(s\).
The key of Q-learning is to continuously learn \(Q(\cdot,\cdot)\) while using the learned estimates to select actions as we go. First recall Q-value iteration:
\[ Q_{t+1}(s,a) = r(s,a) + \gamma \sum_{s' \in S} T(s, a, s') \left(\max_{a' \in A} Q_{t}(s', a')\right). \] In Q-learning, these updates are approximated using sample observations. As we operate our system with Q-learning, after an action \(a_t\) is chosen at time step \(t\), the state of the system changes from state \(s_t\) to \(s_{t+1}\), and a reward \(R(s_t, a_t, s_{t+1})\) is obtained. At that point we update the \((s_t, a_t)\) entry of the Q-function estimate as follows:
Here \(\alpha_t\) is a decaying (or constant) sequence of probabilities. A pseudocode of Q-learning is given below.
| Algorithm : Pseudocode for Q-learning |
Input: Given starting state distribution \(D_0\);
Initialization: Take \(\widehat{Q}\) to be an empty array
repeat for \(e = 1, 2, \dots\) until change in \(\widehat{Q}\) is small
\(s_0 \sim D_0\).
Select step sizes \(\alpha_0, \alpha_1, \dots\)
repeat for \(t = 1, 2, \dots\) until epoch is terminated
Select an action \(a_t\).
Observe the next state \(s_{t+1}\) and the reward \(R(s_t, a_t, s_{t+1})\).
Take \(\delta_t := \left(R(s_t, a_t, s_{t+1}) + \gamma \max_{a' \in A} \widehat{Q}(s_{t+1}, a')\right) - \widehat{Q}(s_{t}, a_t)\)
\(\widehat{Q}(s_{t}, a_t) \leftarrow \widehat{Q}(s_{t}, a_t) + \alpha_t \delta_t\)
We attempt to balance exploration and exploitation. With a high probability, we decide on action \(a'\) that maximizes \(Q_t(s_{t+1}, \cdot)\) - this is exploitation. However, we leave some possibility to explore other actions, and occasionally decide on an arbitrary (random) action - this is exploration. The key of the Q-learning update equation (9.6) is a weighted average of the previous estimate \(Q_t(s_t,a_t)\) and a single sample of the right hand side of the Bellman equation of Q-value function. Miraculously as the system progresses under such a control, this scheme is able to estimate the Q-function and hence control the system well.
For the above Q-learning algorithm, the following convergence result holds.
Theorem 9.6 (Watkins and Dayan 1992): Suppose that the rewards are bounded and the learning rates satisfy \[ \sum_{i=1}^\infty \alpha_{n^i(s,a)} = \infty, \qquad \mbox{and} \qquad \sum_{i=1}^\infty \alpha_{n^i(s,a)}^2 < \infty, \] for all \((s,a) \in S\times A\). Let \(\widehat{Q}_k(s,a)\) be the estimate of \(Q(s,a)\) in round \(k\).
Then, \(\widehat{Q}_k(s,a) \to Q(s,a)\) as \(k \to \infty\) almost surely for all \((s,a) \in S\times A,\) where \({n^i(s,a)}\) is the \(i^{th}\) instant the action \(a\) is selected in state \(s\).
The above theorem essentially states that if all the actions are selected in all the states infinitely often, and the learning rate decreases to zero but not too quickly, then Q-learning converges. This property shows that (at least in principle), systems controlled via Q-learning may still be controlled in an asymptotically optimal manner, even without explicit knowledge of the underlying transitions \(T(s, a, s')\).
Issue: It is difficult to implementation of Q-learning algorithm for many practical applications where the state space is large (possibly continuous). There can be many states to visit and keep track of. The following images illustrate this point.
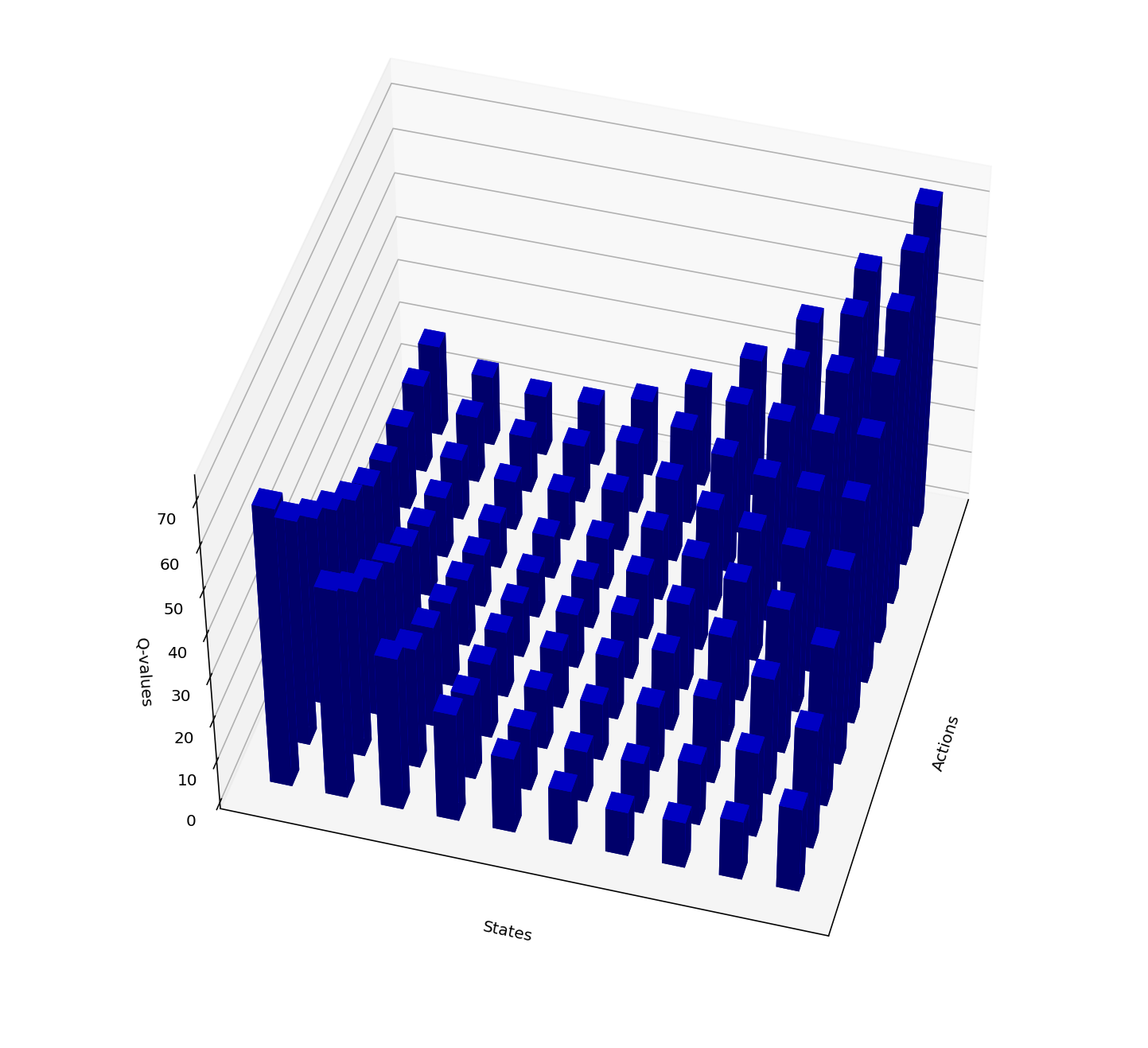
An example of optimal Q-values where neighboring state-action pairs have similar Q-values.
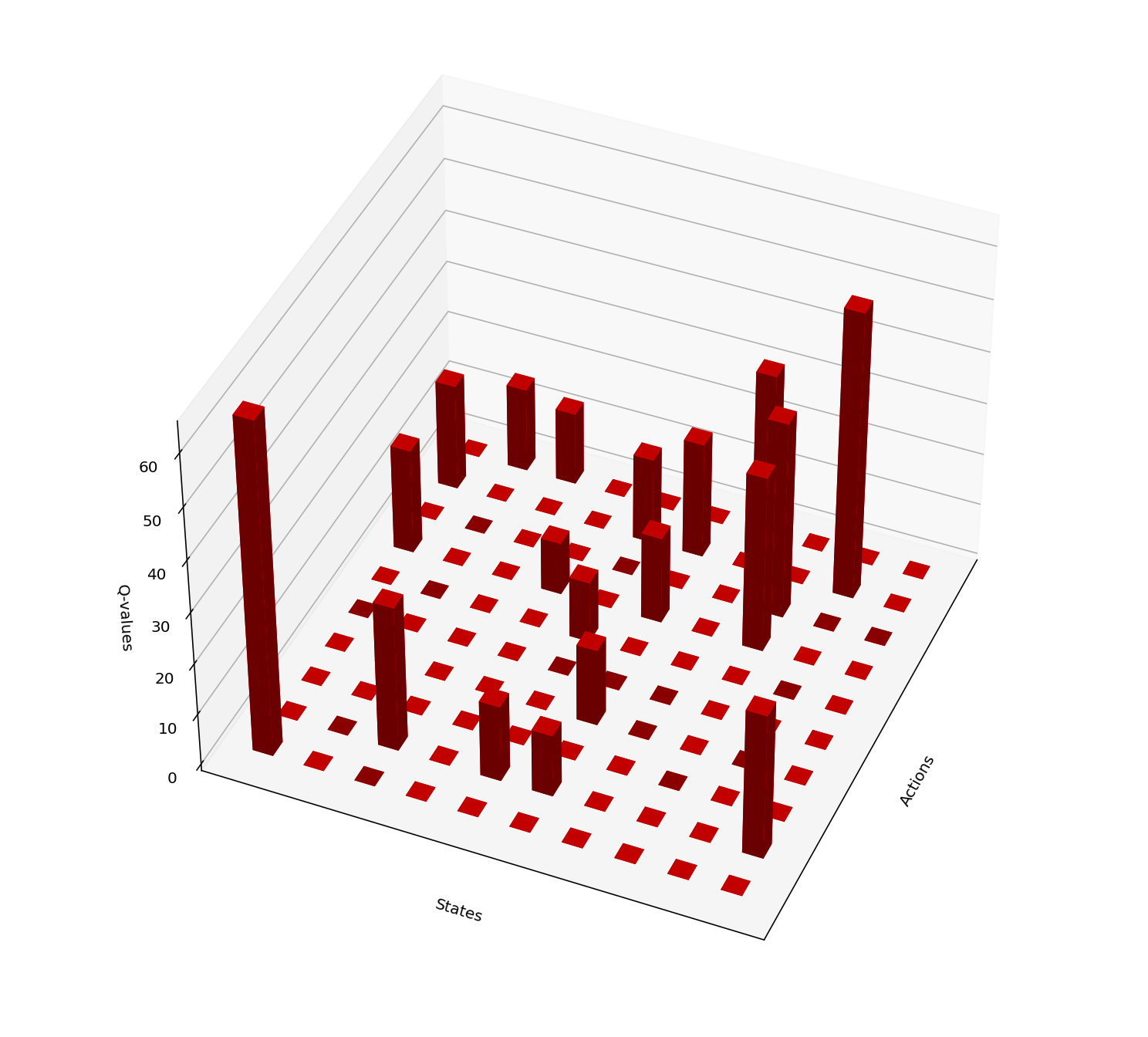
Estimation optimal Q-values using Q-learning. Unexplored state-action pairs carry zero Q-values
9.5 Deep Reinforcement learning
To overcome the scalability issue highlighted above, instead of updating the Q-value of each state-action pair, we would like use what we have learned about already visited states to approximate Q-values of similar states that not yet visited. This is possible even if already visited states are small in number. Deep RL addresses this issue via function approximation using a deep neural network.
The main idea of such methods is to use function approximation to learn a parametric approximation \(Q(s, a; \theta)\) of \(Q(s,a)\). For instance, the approximate function \(Q(s,a; \theta)\) can be linear in \(n\) parameters \(\theta\) and \(n\) features \(x(s,a)\) as follows: \[ Q(s,a; \theta) = \theta_0 + \theta_1 x_1(s,a) + \cdots + \theta_n x_n(s,a). \] Or, more generally, we can use a DNN to have an approximation of the form \[ Q(s,a; \theta) = f_{\theta}(x(s,a)), \] where \(f_{\theta}\) represents the DNN with parameters \(\theta =\) (weights, biases). Using such function approximation, for a given \(\theta\), the Q-value function can be computed approximately for unseen state-action pairs \((s,a)\). The key point to note that instead of learning \(|S| \times |A|\) matrix of Q-values, function approximation based Q-learning learns \(\theta\). That is, we are trying to find a \(\theta\) such that the Bellman equations \[\begin{align} Q(s, a; \theta) &= r(s,a) + \gamma \sum_{s' \in S}T(s, a, s') \left[\max_{a' \in A} Q(s',a'; \theta)\right]\\ &= \mathbb{E}_{s' \sim T(s, a, s')}\left[ R(s,a, s') + \gamma \max_{a' \in A} Q(s',a'; \theta)\right] \end{align}\] can be approximated for every state-action pair \((s,a) \in S\times A\). We do this approximation by minimizing squares loss function:
\[\begin{align} \ell_\theta(s,a) = \mathbb{E}_{s' \sim T(s,a,\cdot)}\left[\left(Q(s,a;\theta) - R(s,a,s') - \gamma \max_{a' \in A} Q(s', a'; \theta) \right)^2\right]. \end{align}\] Suppose if we take \[ target(s') := R(s,a,s') + \gamma \max_{a' \in A} Q(s',a'; \theta), \] then we are trying to minimize the expectation of \[ \ell_\theta(s,a,s') = \left(Q(s,a;\theta) - target(s')\right)^2. \] The following Q-learning algorithm uses gradient descent to optimize this loss for the observation \(s'\). When we compare this with supervised learning, \(target(s')\) acts like actual label and \(Q(s,a;\theta)\) acts like prediction. However, unlike in supervised learning, \(target(s')\) and \(Q(s,a;\theta)\) are not independent.
| Algorithm : Function approximation based Q-learning |
Fix an initial state \(s_0\)
Initiate the parameters \(\widehat \theta\)
repeat for \(e = 1, 2, \dots\) until the termination condition is satisfied
Start in \(s_0\).
Select step sizes \(\alpha_0, \alpha_1, \dots\)
repeat for \(t = 1, 2, \dots\) until \(s_t\) is not a terminal state
Select an action \(a_t\). Probably using the greedy strategy \(a_t \in \arg\max_{a}Q(s_t, a; \widehat \theta)\)
Observe the next state \(s_{t+1}\) and the reward \(R(s_t, a_t, s_{t+1})\).
Take \(\, \delta_t := \left(R(s_t, a_t, s_{t+1}) + \gamma \max_{a' \in A} Q(s_{t+1}, a'; \widehat \theta)\right) - Q(s_{t}, a_t; \widehat \theta)\)
\(\widehat\theta \leftarrow \widehat\theta + \alpha_t \delta_t \nabla_{\widehat\theta} Q(s_t,a_t; \widehat\theta)\)
9.5.1 Deep Q-learning Network (DQN)
In the previous chapters, we have seen several deep neural networks that provide function approximations for models in supervised learning, providing an approximation of the mapping from inputs to the corresponding outputs. Deep Q-learning networks use deep neural networks for the function approximation in the last algorithm, where the parameters \(\theta\) are weights and biases of the deep neural network.
9.5.1.1 Key points to note about DQN
In DQN, the input feature \(x\) at time \(t\) is formed by the state-action pair \((s_t, a_t)\). For a given \(\theta_t\), the output \(f_{\theta_t}(x)\) is the prediction for \(Q(s_t, a_t; \theta_t)\).
Since we do not directly have a target label, we ‘bootstrap’ from the current \(Q\)-network (that is, current parameters \(\theta_t\)) to generate a target label as \(R(s_t, a_t, s_{t+1}) + \gamma \max_{a \in A} Q(s_t, a; \theta_{t})\).
Then to update the parameters \(\theta\), we use gradient descent on squared loss function.
9.5.1.2 Challenges
Exploration: Recall that the goal is to simultaneously minimize the loss functions \(\{\ell_{\theta}(s, a) : (s,a) \in S \times A\}\). The number of samples available for each \((s,a)\) depends on how much we explore \(s\) and \(a\). So, there are different number of samples available for different state-action pairs. As a consequence, depending on the transition dynamics of the system, accuracies are different for different \((s,a)\) pairs. Of course, there is no need to have high accuracy for every state-action pair. For example, rate \((s,a)\) with low reward can low accuracy without effecting the overall reward. Also, if two state-action pairs have similar features, then it is unnecessary to explore both to learn a good parameter. In summary, it is important to have an adaptive exploration scheme to explore state-action pairs so that the converges of the parameters happens quickly.
Stabilizing: Even though the idea of comparing the prediction \(Q(s, a;\theta )\) to \(target(s')\) is similar to supervised learning, there are several challenges in deep RL that are not present in supervised learning. Minimizing squared loss \(\ell_{\theta}(s,a)\) is here is different from minimizing loss in supervised learning where ‘true’ labels are present, because \(target(s')\) is also an estimate that can change too quickly with \(\theta\). As a consequence, the contraction mapping property of Bellman equation may not be sufficient to guarantee convergence of \(Q\) values. There ere experiments suggesting that these errors can propagate quickly, resulting in slow convergence or even making the algorithm unstable. For more details on this, see Section 4 of (François-Lavet et al. 2018) and the references there.
9.5.1.3 Example
The idea of function approximation using neural networks is first proposed in (Mnih et al. 2013) for ATARI games using pixel values as features.
Source: (Mnih et al. 2013)
Essentially, they created a single convolutional neural network (CNN) agent that can successfully learn to play as many ATARI 2600 games as possible. The network was not provided with game specific information or hand-designed visual features. The agent learned to play from nothing but the video input of \(210 \times 160 RGB\) at \(60Hz\). Some specifications of the CNN network used are
Each frame of the video is pre-processed to get an input image of \(84 \times 84 \times 4\). This is done because working with the original frame size \(210 \times 160\) pixels with a \(128\) color palette is computationally demanding. This process includes first converting the raw RGB frame to greyscale and then down-sampling it to \(110 \times 84\) image. Final cropping to the size \(84 \times 84\) focuses only on playing area of the image.
The first hidden layer has \(16\) channels with \(8\times 8\) kernel, stride \(4\) and ReLu activation function.
The second hidden layer has \(32\) channels with \(4 \times 4\) kernel, stride \(2\) and ReLu activation function.
The final hidden layer is fully connected linear layer with \(256\) neurons.
The output layer is again a fully connected linear layer with a single out for each action \(a \in A\) (i.e., the output size is \(|A|\)). For the games considered in this paper, the number of actions \(|A|\) varied between \(4\) and \(18\).
Watch the following video explaining the paper (Mnih et al. 2013) in some more details.
9.5.1.4 Heuristics used in (Mnih et al. 2013) to limit the instability
- Note that in the deep Q-learning algorithm the parameters \(\theta\) for the \(target\) is updated after every iterations. This can cause high correlation between the target and the prediction and, as a consequence, instabilities can propagate quickly. To overcome this, (Mnih et al. 2013) updates the parameters of the \(target\) only after every \(C\) iterations, while continue to learn the parameters in each iteration. Larger the \(C\) lesser the correlation. However, if \(C\) is too large, the parameters in \(target\) are far from better parameters, creating errors. So, it is important to select a moderate \(C\). The following figure illustrates this point (screenshot from (François-Lavet et al. 2018)).
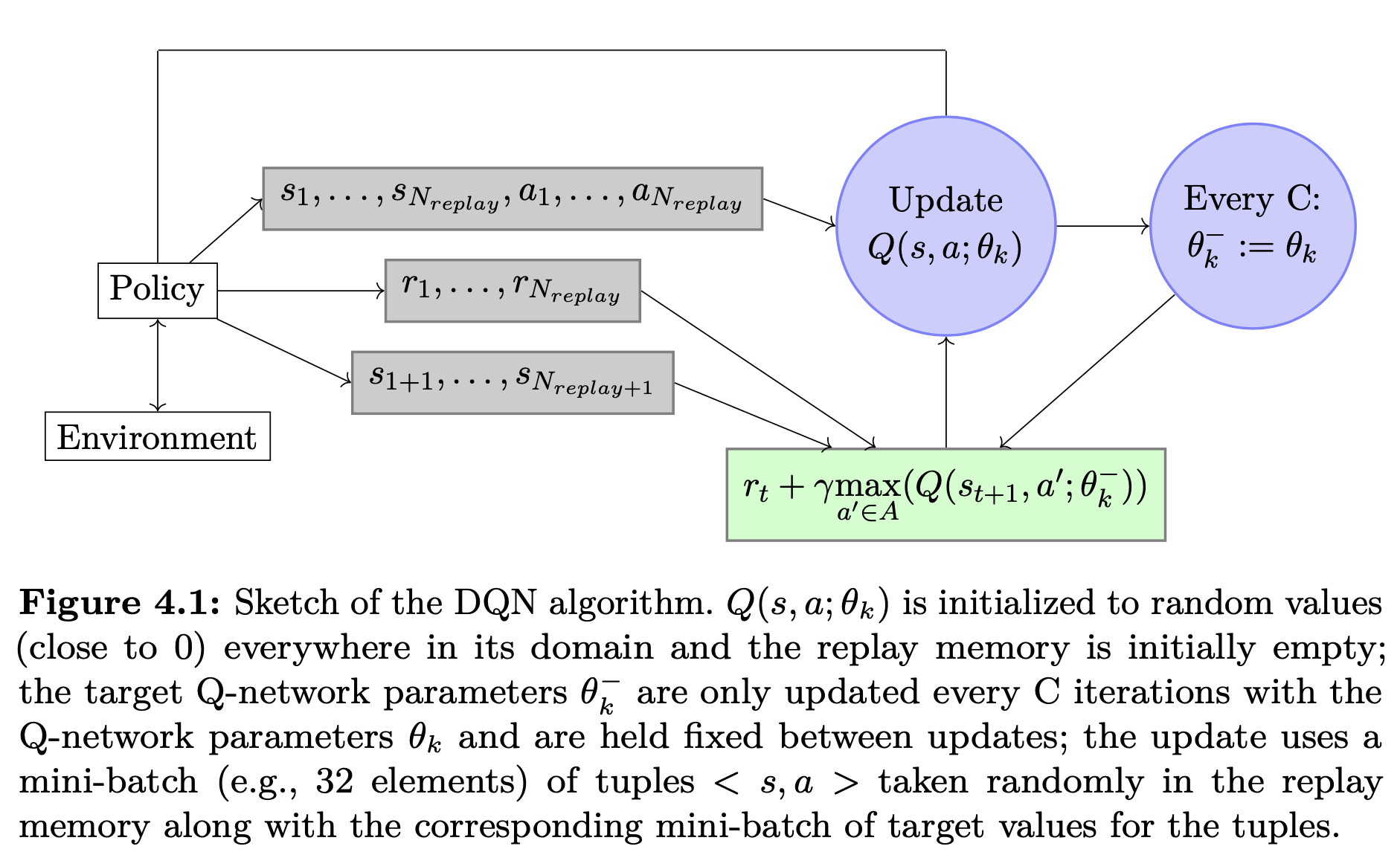
Instead of greedy strategy in selecting an action in each iteration, they use \(\epsilon\)-greedy strategy: selects an action using greedy strategy with probability \(1- \epsilon\) and selects a random action with probability \(\epsilon\).
Since the scale of the scores varies from game to game, in addition to the above heuristics, to limit the the scale of error derivatives and make the network easier to use across multiple games, the rewards are clipped as follows: all positive rewards are \(1\), all negative rewards are \(-1\), and \(0\) rewards are unchanged.
9.5.1.5 Double DQN
The max operation in computing \(target(s') = R(s,a,s') + \gamma \max_{a' \in A} Q(s',a; \theta)\) uses the same parameter values to select and evaluate an action. This can result in overestimation of Q-learning values. To remedy this issue, in double DQN (DDQN), the target value is computed as \[ target(s') = R(s,a,s') + \gamma Q\left(s', \arg\max_{a' \in A}Q\left(s, a' ; \theta_k \right) ; \theta_k^- \right), \] where \(\theta_k\) is the current update and \(\theta_k^-\) is the current batch update of the parameters.
9.5.1.6 Distributional DQN
So far, in all the methods, the goal is to approximate the expected total discounted reward (either value function or Q-value function). Another richer approach is to find an optimal distribution of the cumulative reward. Such approach provides more information about the randomness of the rewards and transitions of the agent. Suppose \(Z^\pi: S\times A \to \mathbb R\) is a random variable for each state-action pair with the distribution of cumulative reward obtained under the policy \(\pi\), then it has expectation: \[ Q^\pi(s,a) = \mathbb{E}\left[ Z^\pi(s,a) \right] \] for every state-action pair \((s,a)\). The recursive relationship for the random reward is given by \[ Z^\pi(s,a) = R(s,a,s') + \gamma Z^\pi(S',A'), \] where \(S'\) and \(A'\) denote the next state and the next action, which are random in nature. Note that \(A' \sim \pi(\cdot| S')\).
Recently such distributional DQN are used in practice and they are shown to exhibit additional advantages; refer to (Bellemore et al 2017), (Dabney et al 2017), and (Rowland et al 2018) for more details.
Page built: 2021-03-04 using R version 4.0.3 (2020-10-10)